首页
关于
Search
1
短信验证码(接码)平台
8,064 阅读
2
【教程】非常详细的Wireshark抓取抖音直播的OBS推流地址和密钥
5,775 阅读
3
【教程】教你使用VISA信用卡时的信息怎么填
5,650 阅读
4
【教程】搭建咸鱼之王私服,附源码下载
5,429 阅读
5
【工具】国内免加速免注册免费使用ChatGPT AI对话机器人
5,389 阅读
学习笔记
安装笔记
好用软件
随便写写
正经科研
TODO清单
登录
/
注册
找到
4
篇与
相关的结果
2023-06-06
【报告】当“无线通信”遇到“图神经网络”——简单理解
GNN与无线通信的结合使用
调研与报告
# GNN
# 汇报
# 图神经网络
# 无线通信
哗啦啦
3年前
0
452
0
2023-03-08
【调研】分布式GNN训练的综述汇报
分布式GNN训练综述
调研与报告
# 科研
# GNN
哗啦啦
3年前
0
485
0
2023-03-05
【知识点】有关分布式GNN训练的一些问答
分布式GNN
知识点与小技巧
# 科研
# GNN
# 分布式
哗啦啦
3年前
0
432
1
2022-11-15
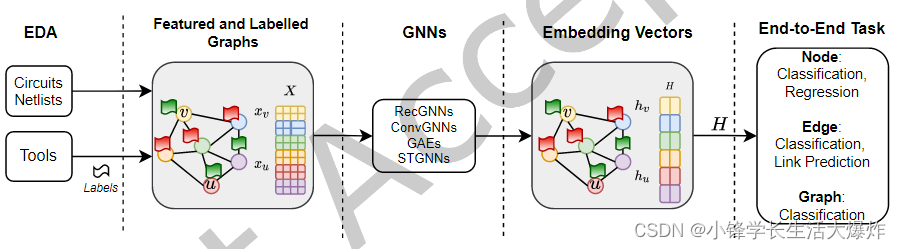
【阅读】A Comprehensive Survey on Electronic Design Automation and Graph Neural Networks——EDA+GNN综述翻译
翻译的一篇很新很全的GNN+EDA综述
调研与报告
# 深度学习
# GNN
# EDA
哗啦啦
4年前
0
174
0