首页
关于
Search
1
短信验证码(接码)平台
6,784 阅读
2
【教程】非常详细的Wireshark抓取抖音直播的OBS推流地址和密钥
5,322 阅读
3
【工具】自动获取抖音直播的OBS推流地址和密钥
5,001 阅读
4
【教程】搭建咸鱼之王私服,附源码下载
4,661 阅读
5
【教程】教你使用VISA信用卡时的信息怎么填
4,635 阅读
学习笔记
安装笔记
好用软件
随便写写
正经科研
TODO清单
登录
/
注册
推荐文章
推荐
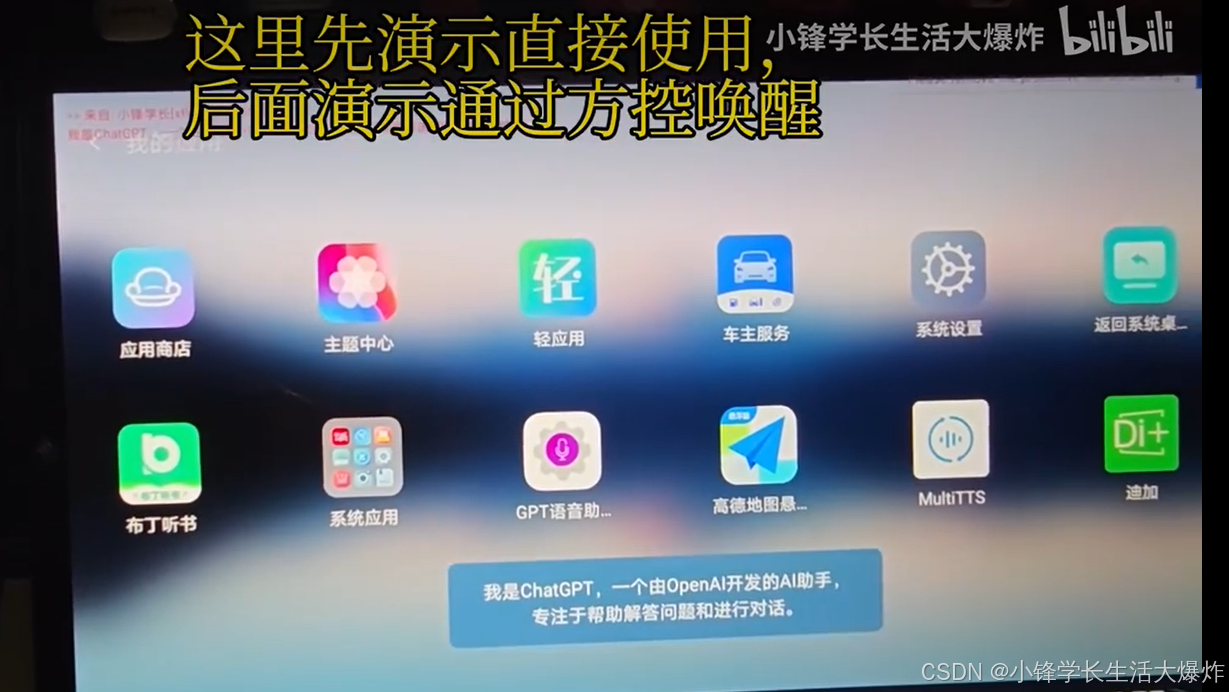
【教程】比亚迪车机接入AI大模型语音助手
推广宣传
超便宜的轻量应用服务器
最新发布
2022-09-04
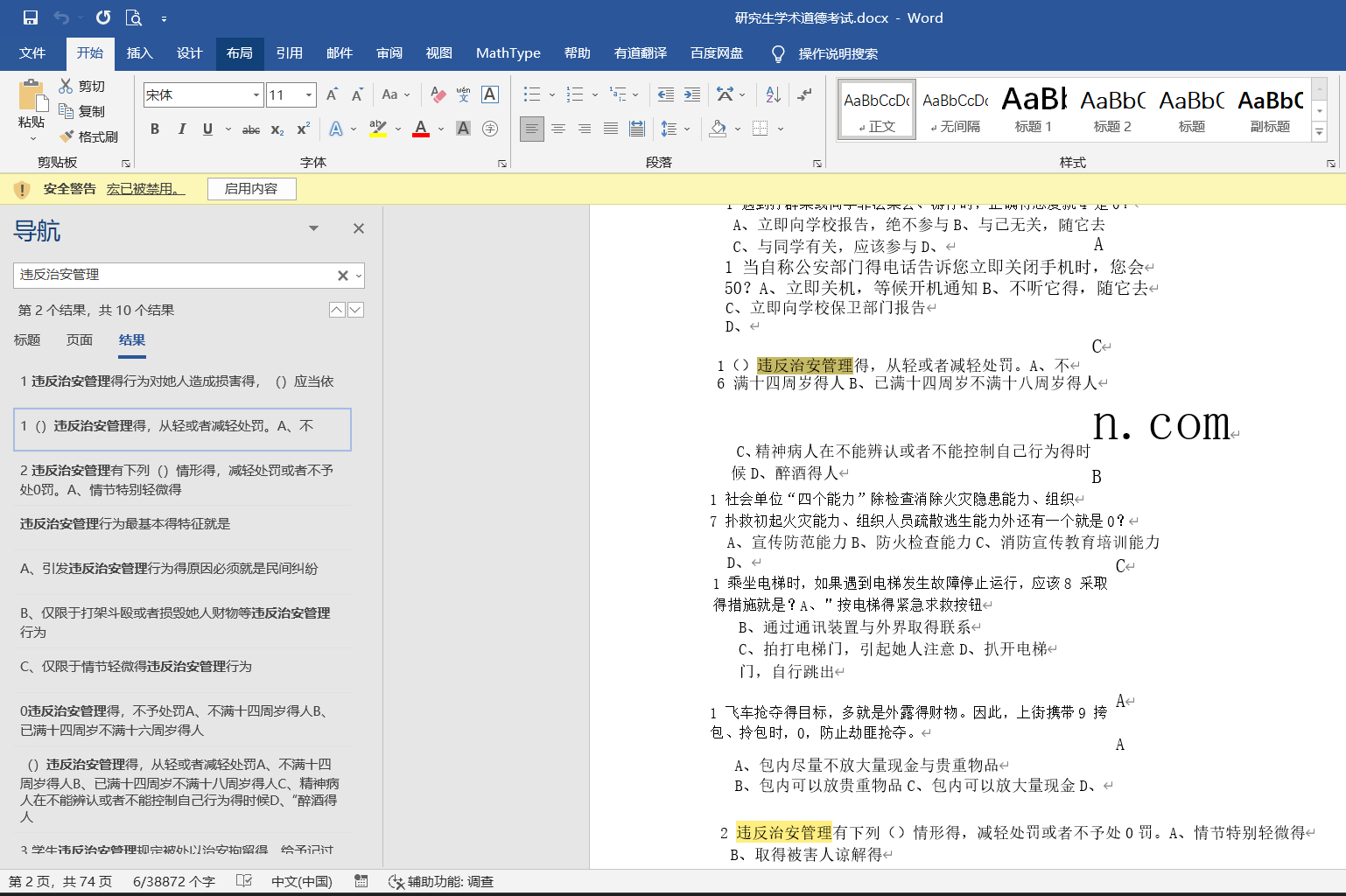
研究生学术道德考试 参考答案 Word可搜索版
仅供学习参考
福利教程
哗啦啦
4年前
0
275
0
2022-09-02
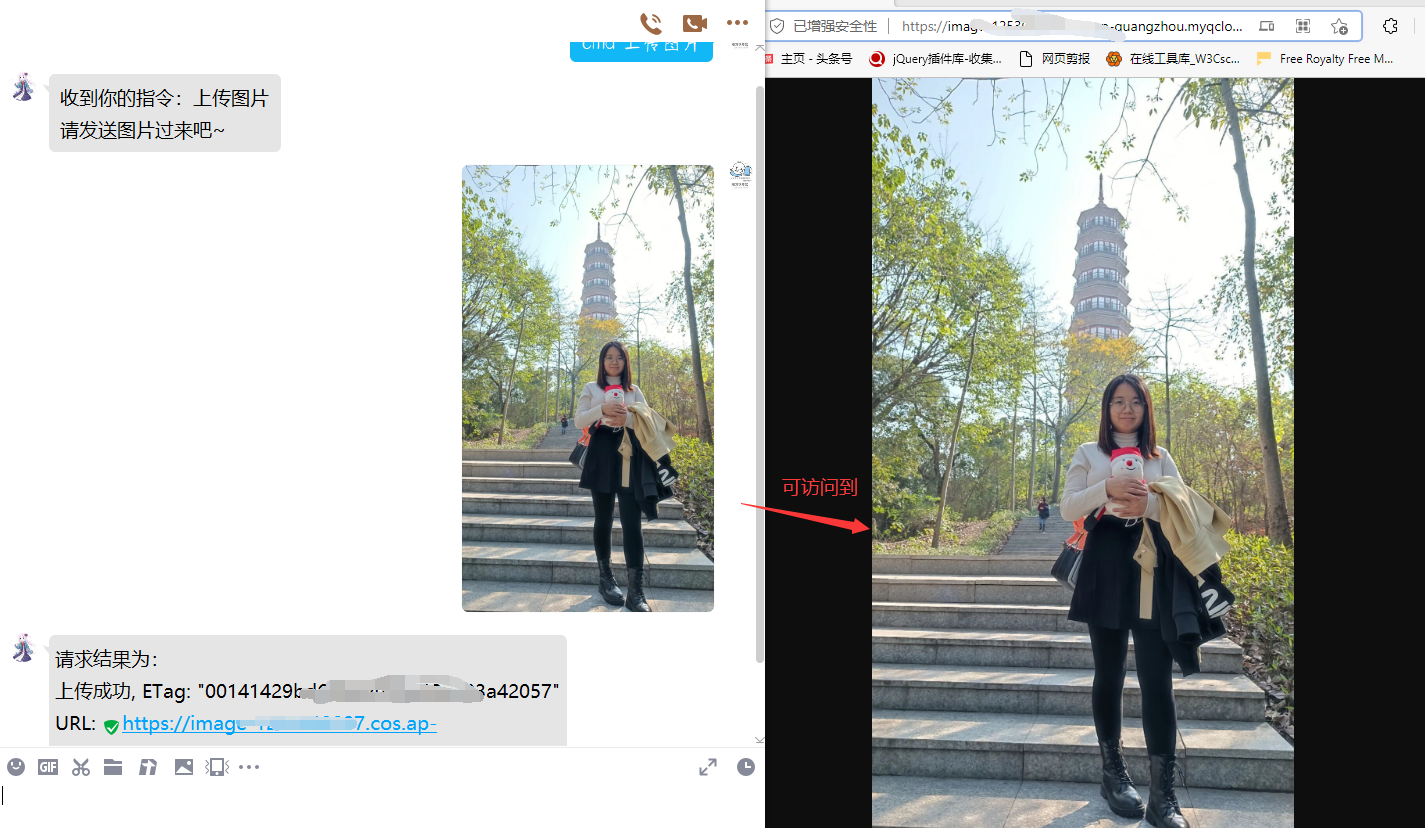
【教程】万字长文保姆级教你制作自己的多功能QQ机器人
篇幅较长且保姆级详细,建议收藏后慢慢看
制作小工具
# python
# mirai
# QQ机器人
# QQ
哗啦啦
4年前
1
1,096
0
2022-09-01
开学季-腾讯云校园大使开始招募了~
不限学历与年级~
福利教程
# 校园大使
# 腾讯云
# 服务器
哗啦啦
4年前
0
329
0
2022-08-22
tkinter获取文件名与可视化拖拽布局助手
tkinter获取文件名与可视化拖拽布局助手
Python
# python
# tkinter
# 可视化
哗啦啦
4年前
0
380
0
2022-08-22
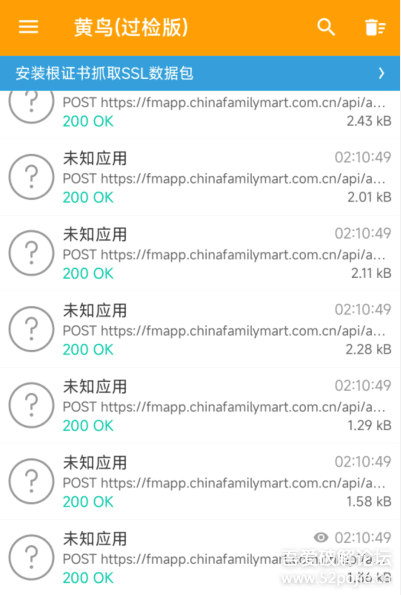
全家Fa米家app抓包——做自动签到领Fa米粒
可以做个自动签到领Fa米粒
Python
# python
# Famijia
# 抓包
# xiaohuangn
哗啦啦
4年前
0
440
0
上一页
1
...
31
32
33
...
40
下一页
 推荐
推荐