首页
关于
Search
1
短信验证码(接码)平台
6,765 阅读
2
【教程】非常详细的Wireshark抓取抖音直播的OBS推流地址和密钥
5,313 阅读
3
【工具】自动获取抖音直播的OBS推流地址和密钥
4,994 阅读
4
【教程】搭建咸鱼之王私服,附源码下载
4,652 阅读
5
【教程】教你使用VISA信用卡时的信息怎么填
4,629 阅读
学习笔记
安装笔记
好用软件
随便写写
正经科研
TODO清单
登录
/
注册
推荐文章
推荐
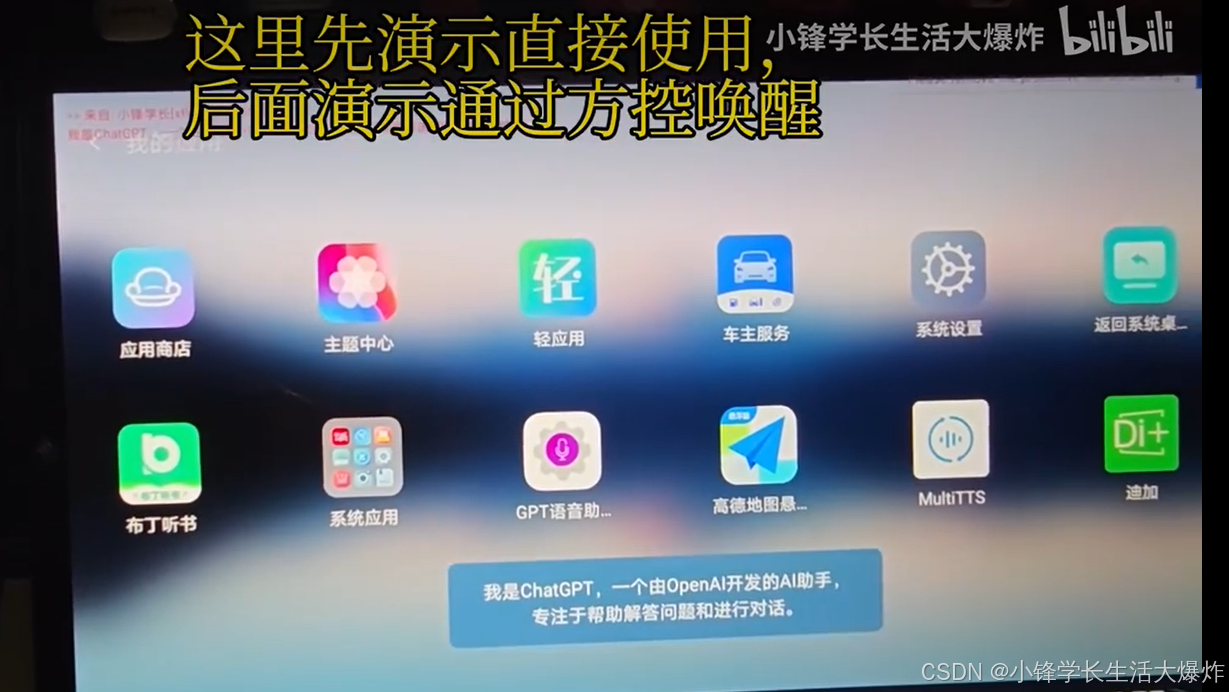
【教程】比亚迪车机接入AI大模型语音助手
推广宣传
超便宜的轻量应用服务器
最新发布
2022-09-18
国庆节了给头像添加渐变红旗和国旗
国庆了,渐变红旗头像可以安排上了
福利教程
# 头像
哗啦啦
4年前
0
239
0
2022-09-17
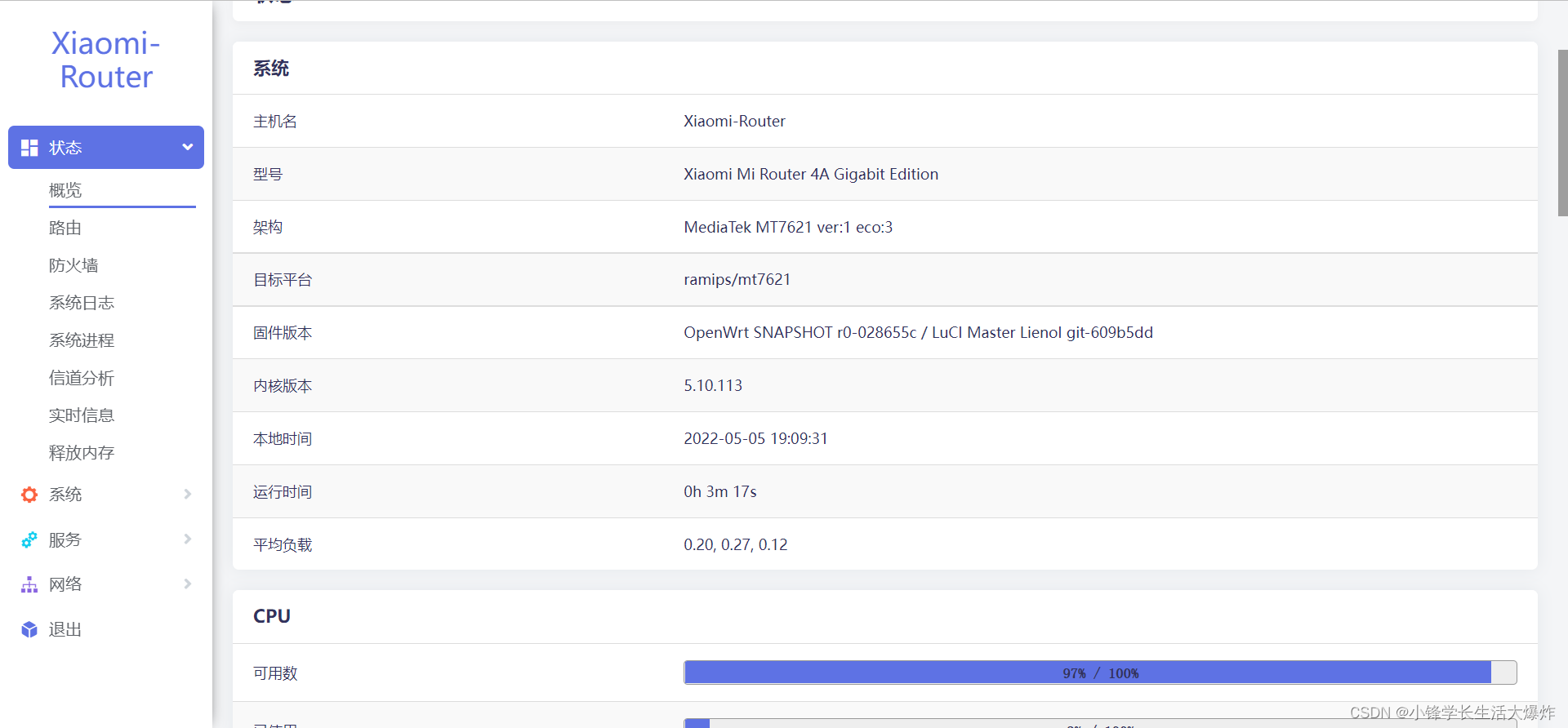
小米路由R4A千兆版安装breed+OpenWRT教程(全脚本无需硬改)
图文并茂很详细
Linux
# 路由器
# OpenWrt
# breed
哗啦啦
4年前
1
1,711
1
2022-09-16
API收集整理
常用免费API
经验分享
# API
哗啦啦
4年前
0
249
0
2022-09-16
羊了个羊小游戏 脚本全自动刷分霸榜
run一下,很快啊~
福利教程
哗啦啦
4年前
5
750
0
2022-09-15
两行解决matplotlib显示中文乱码的问题
是真的秀
知识点与小技巧
# matplotlib
哗啦啦
4年前
0
331
0
上一页
1
...
29
30
31
...
40
下一页
 推荐
推荐

 推荐
推荐