首页
关于
Search
1
短信验证码(接码)平台
6,520 阅读
2
【教程】非常详细的Wireshark抓取抖音直播的OBS推流地址和密钥
5,197 阅读
3
【工具】自动获取抖音直播的OBS推流地址和密钥
4,914 阅读
4
【教程】搭建咸鱼之王私服,附源码下载
4,485 阅读
5
【教程】教你使用VISA信用卡时的信息怎么填
4,450 阅读
学习笔记
安装笔记
好用软件
随便写写
正经科研
TODO清单
登录
/
注册
找到
5
篇与
相关的结果
2022-03-19
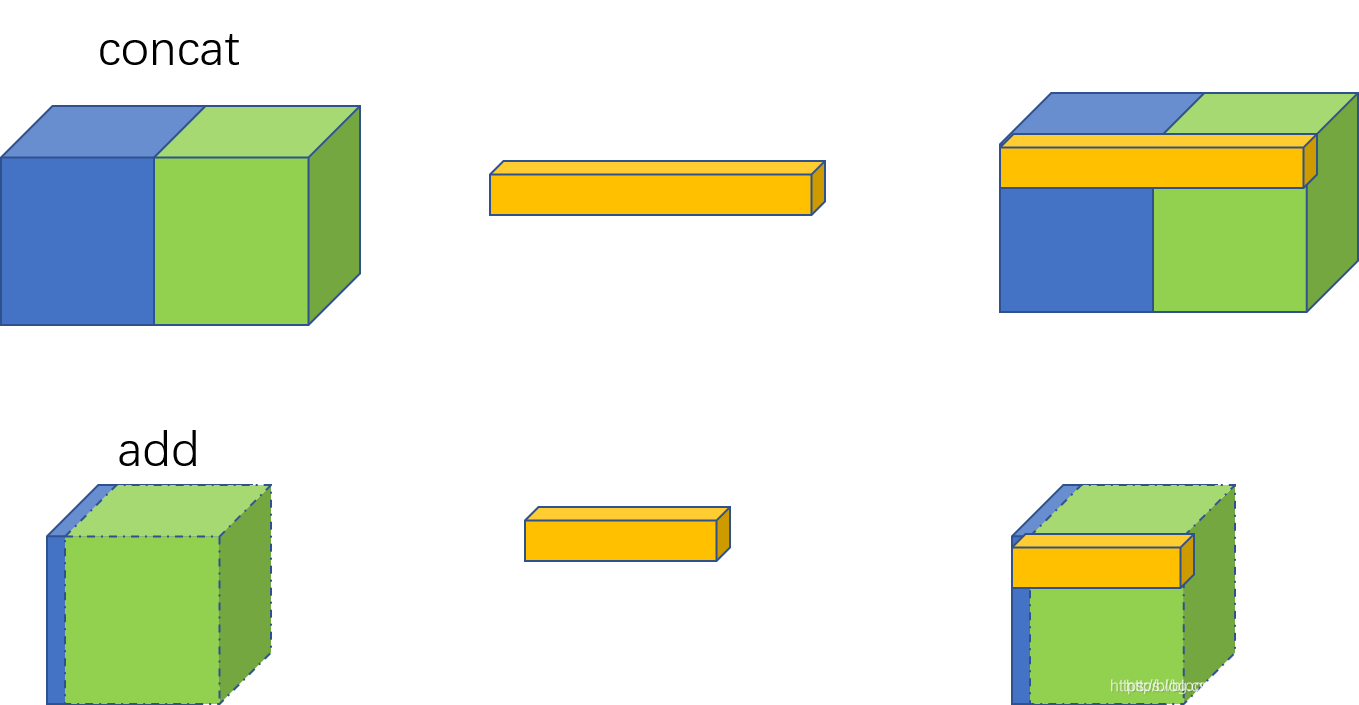
CNN中concat与add的区别
整理自网上
深度学习
哗啦啦
4年前
0
446
0
2022-03-16
SIFT的PyTorch实现
若需自取~
深度学习
# SIFT
哗啦啦
4年前
0
384
0
2022-03-15
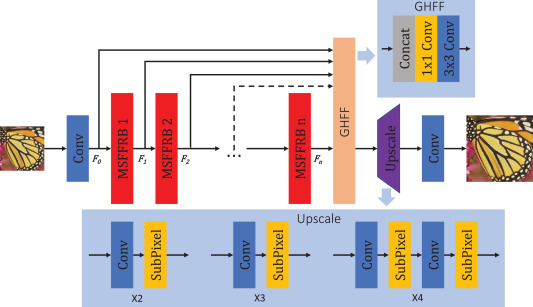
多尺度特征融合的各种模型结构
可能有点参考价值...
深度学习
调研与报告
# 特征ronghe
# 多尺度
# CNN
# 卷积网络
哗啦啦
4年前
0
573
0
2022-01-12
HardNet改进和变体详解及对比
绝对是你想找的!
深度学习
调研与报告
哗啦啦
4年前
0
393
0
2021-12-19
CNN上加Attention
CNN上加Attention
深度学习
知识点与小技巧
哗啦啦
5年前
0
345
0