首页
关于
Search
1
短信验证码(接码)平台
6,758 阅读
2
【教程】非常详细的Wireshark抓取抖音直播的OBS推流地址和密钥
5,308 阅读
3
【工具】自动获取抖音直播的OBS推流地址和密钥
4,992 阅读
4
【教程】搭建咸鱼之王私服,附源码下载
4,649 阅读
5
【教程】教你使用VISA信用卡时的信息怎么填
4,624 阅读
学习笔记
安装笔记
好用软件
随便写写
正经科研
TODO清单
登录
/
注册
推荐文章
推荐
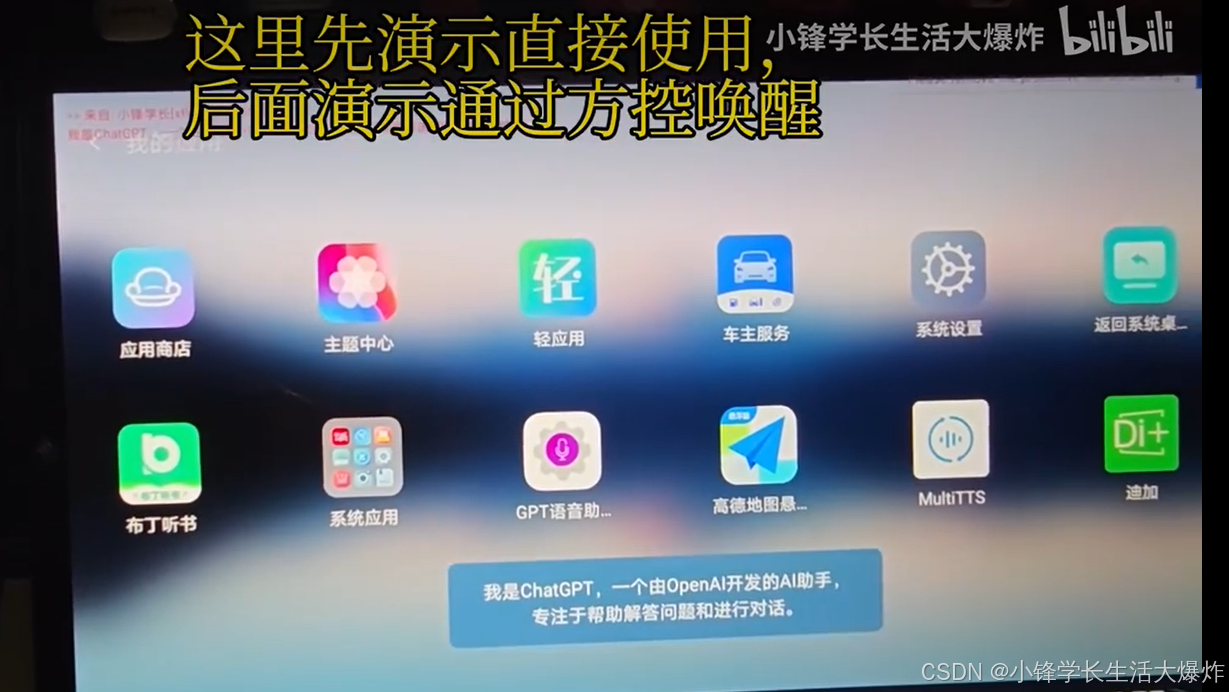
【教程】比亚迪车机接入AI大模型语音助手
推广宣传
超便宜的轻量应用服务器
最新发布
2023-08-17
【福利】Vmware Fusion for Mac v13.0.2 正版软件和序列号key
正版序列号!
福利教程
# 工具
# 教程
# 福利
# mac
哗啦啦
3年前
1
430
0
2023-08-11
【踩坑】学术论文中的时态问题,以实际论文为例
好坑啊
知识点与小技巧
# 科研
哗啦啦
3年前
0
398
0
2023-08-07
【福利】亲测!可用Jetbrains全家桶免费激活方法!
非常好用!
经验分享
福利教程
# 工具
# 教程
# 福利
哗啦啦
3年前
0
311
0
2023-08-03
【Win/Mac】Adobe Acrobat Pro DC 2023 和谐版
可以试试
Windows软件
福利教程
# Windows
# 工具
# 教程
# 福利
# mac
哗啦啦
3年前
0
624
0
2023-08-01
【软件】TickTick 滴答清单专业版破解版
白嫖白嫖
Windows
Android
福利教程
# 工具
# 教程
# 安卓
# 福利
# mac
哗啦啦
3年前
2
1,249
0
上一页
1
...
14
15
16
...
40
下一页
 推荐
推荐